The Invisible Website: Why AI Crawlers Cannot Read Most Modern Business Websites
Most modern business websites are technically invisible to AI crawlers. This essay explains the structural reasons why, and what organizations must do to become readable to the systems that now mediate business decisions.

A company can have a well-designed website, a content team, a functioning SEO program, and consistent traffic — and still be effectively invisible to the AI systems that now mediate business decisions. This is not a content problem. It is a structural one, and most organizations have not yet recognized it.
Key Takeaways
- Modern JavaScript-heavy websites are often unreadable to AI crawlers that cannot execute client-side rendering
- Dynamic content that loads after page render — menus, product descriptions, pricing, service details — is frequently missed entirely by AI systems
- Structured data implementation gaps mean AI systems cannot reliably identify what an organization is, what it does, or who it serves
- AI crawlers and search engine crawlers are not the same, and optimizing for Google does not guarantee AI readability
- Single-page applications (SPAs) built on React, Vue, or Angular present particular challenges for AI content extraction
- PDF-heavy and gated content strategies effectively hide organizational knowledge from AI systems that cannot authenticate or parse unstructured documents
- The technical gap is fixable, but it requires infrastructure decisions that go beyond marketing and into engineering
- Organizations that address technical AI readability now build a compounding advantage as AI-mediated discovery grows
Quick Answer
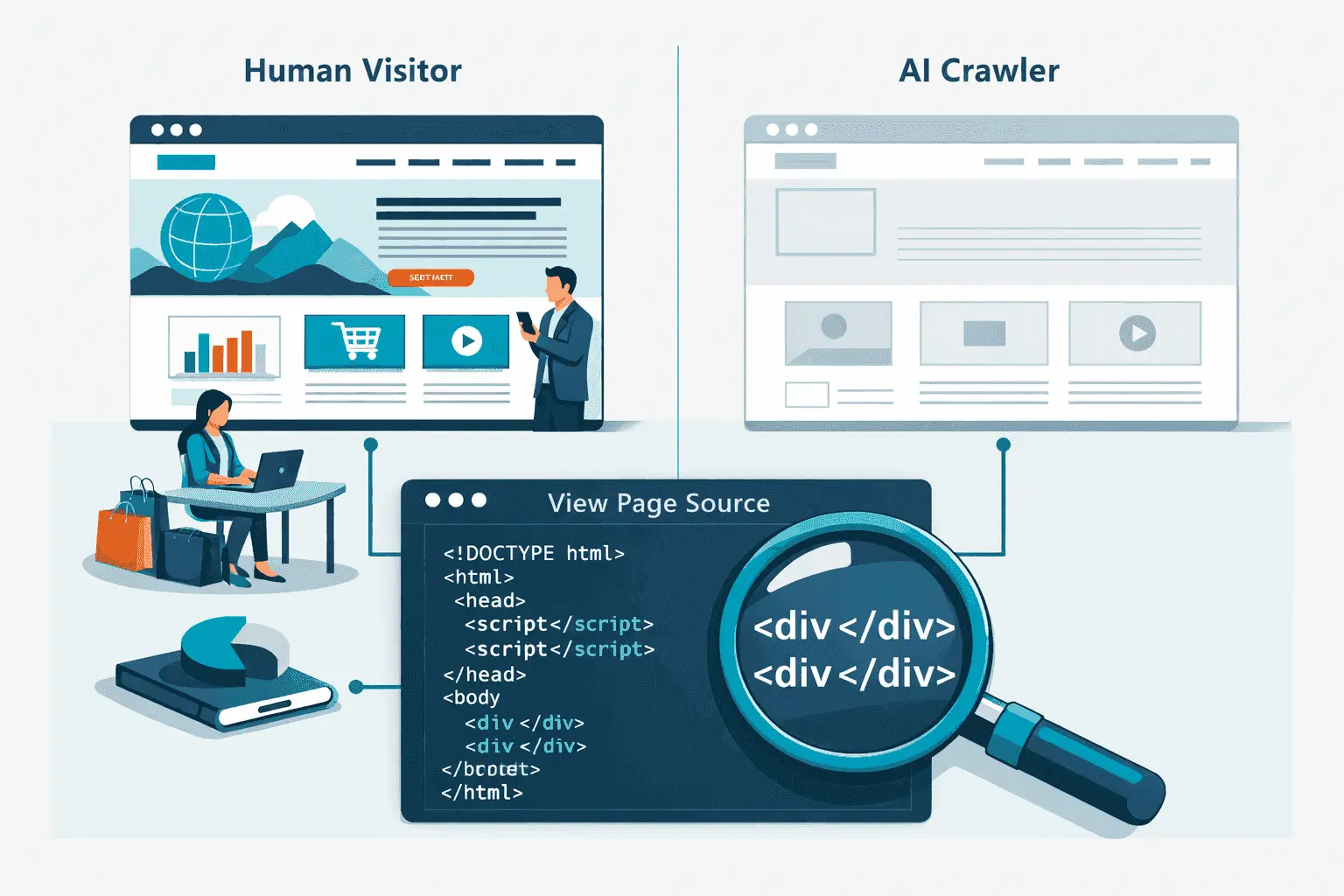
Most AI systems that power tools like ChatGPT, Perplexity, and Claude build their knowledge from web content collected during training or via real-time retrieval. If your website renders its content through JavaScript that executes in the browser, loads content dynamically after the initial page request, or requires authentication to access key information, AI crawlers will encounter an empty or incomplete page. The content exists for human visitors but not for the machines that now influence how your organization is discovered, described, and recommended.
How AI Crawlers Differ from Search Engine Crawlers
The assumption that a website performing well in Google search is also readable to AI systems is incorrect. Google has invested heavily in JavaScript rendering infrastructure — Googlebot can execute JavaScript, wait for dynamic content to load, and index the result. Most AI training crawlers and retrieval systems do not have this capability.
Traditional AI training crawlers work similarly to early-generation search bots: they fetch the raw HTML of a page and extract whatever text is present in that initial response. If a React or Next.js application returns a near-empty HTML shell with a <div id="root"></div> and loads its content via JavaScript after render, the crawler receives almost nothing.
Retrieval-augmented AI systems that fetch live web content face the same problem. When Perplexity or a ChatGPT browsing plugin fetches your website to answer a user's question, it typically fetches the HTML and parses it. JavaScript execution is limited or absent in most retrieval pipelines.
The practical consequence: a business website built entirely as a single-page application may show up beautifully in a browser and rank reasonably in Google — while returning almost no useful content to any AI system attempting to read it.
The JavaScript Rendering Problem
The majority of modern business websites are built on JavaScript frameworks: React, Vue, Angular, Next.js in client-side rendering mode. These frameworks deliver applications rather than documents. The server sends minimal HTML and a large JavaScript bundle. The browser executes the JavaScript, fetches data from APIs, and assembles the visible page.
This architecture creates multiple AI readability failure points.
Shell HTML with no content: When an AI crawler requests a page, it may receive only the application shell — navigation placeholders, an empty main container, and script tags. None of the actual page content is present in the initial HTML response.
Client-side data fetching: Service descriptions, team bios, case studies, pricing information, and other strategically important content is often loaded from a separate API after the page shell renders. AI crawlers that don't execute JavaScript never trigger these API calls and never see the content.
Lazy loading and scroll triggers: Content that loads as a user scrolls down the page will never be seen by a crawler that doesn't simulate browser scroll behavior. Product catalogs, testimonial sections, and detailed service descriptions are commonly implemented this way.
Modal and tab content: Information stored behind UI interactions — clicking a tab to see service details, opening a modal to view case study content — is structurally inaccessible to crawlers that don't interact with the page.
Server-Side Rendering and Static Generation as Solutions
The most reliable fix for AI readability is ensuring that key content is present in the initial HTML response from the server, before any JavaScript executes. Two approaches address this.
Server-Side Rendering (SSR) generates the full HTML of each page on the server for each request, delivering complete content to any client — including AI crawlers — in the initial response. Next.js, Nuxt.js, and SvelteKit all support SSR. Organizations using these frameworks in client-side rendering mode can migrate to SSR without rebuilding their application.
Static Site Generation (SSG) pre-renders pages at build time, producing static HTML files that any crawler can read directly. For content that doesn't change with every request — service descriptions, team pages, case studies, blog posts — static generation is the simplest and most robust approach to AI readability.
The key principle is: if the content is important enough for a prospective customer to read, it must be in the HTML that a server delivers, not assembled later by browser JavaScript.
Structured Data: The Layer Most Organizations Skip
Even websites with readable HTML often fail at the next layer of AI comprehension: structured data. Structured data is machine-readable markup embedded in page HTML that tells AI systems and search engines what a page is about, who the organization is, and what information is being presented.
Schema.org markup is the primary standard. Relevant schema types for most business websites include:
Organization: defines the company name, description, founding date, number of employees, industry, contact information, and social profilesService: describes specific services offered, their categories, and their intended audiencesPerson: attributes expert content to named individuals with professional credentialsFAQPage: marks FAQ content in a format AI systems can extract directlyBreadcrumbList: helps AI systems understand site structure and content hierarchyArticleandBlogPosting: marks editorial content with author, date, and topic metadata
Without this markup, AI systems must infer what content means from its formatting and context — an unreliable process that frequently produces incomplete or inaccurate representations. With it, AI systems receive explicit, structured signals about what the organization is and what each page contains.
Most business websites have partial or no structured data implementation. Even organizations with active SEO programs often limit structured data to basic Organization schema and local business markup, missing the richer implementation that supports accurate AI representation.
Gated Content and the Knowledge Visibility Problem
Many organizations store their most authoritative content behind authentication walls: whitepapers, research reports, detailed case studies, and technical documentation. This content represents the organization's actual expertise — the material that, if AI systems could read it, would generate strong and accurate AI representation.
AI systems cannot read it. Authentication walls are absolute barriers for crawlers.
The strategic implication: organizations that gate their best content to generate leads are trading AI visibility for contact information. In markets where AI-mediated discovery is growing, this trade-off is becoming progressively worse. A gated whitepaper generates zero AI visibility. The same content published as a freely accessible article contributes to AI representation every time it is crawled.
This does not mean eliminating all gated content. It means deliberately choosing what to make public for AI readability, recognizing that the freely accessible version of organizational knowledge shapes how AI systems describe the organization to prospective customers, investors, and partners.
PDF Content as a Structural Blind Spot
PDFs present a related problem. Many organizations publish important content — annual reports, capability decks, product specifications, service guides — as PDF files. AI crawlers can sometimes read PDF text, but extraction reliability varies significantly, formatting often disrupts content flow, and PDFs provide no structured data markup.
More critically, PDFs are rarely indexed by AI systems with the same depth as HTML content. A product specification buried in a PDF will almost never be surfaced in AI-generated organizational summaries. The same specification published as an HTML page with appropriate schema markup will be.
The operational implication: any content that exists only in PDF format should be considered semi-invisible to AI systems. Organizations that rely on PDF-based content strategies — common in professional services, financial services, and enterprise technology — have a significant AI readability gap that requires conversion to accessible HTML formats.
Practical Audit: What to Check
Organizations that want to assess their current AI readability should run a focused technical audit across five dimensions.
JavaScript rendering test: Fetch your most important pages using a tool that returns the raw HTML without executing JavaScript. Compare this to what a browser renders. The gap represents content that AI crawlers cannot see.
Structured data validation: Use Google's Rich Results Test or Schema.org validator to check what structured data exists on key pages. Identify missing schema types and incomplete implementations.
Content accessibility mapping: Identify which content on your website requires JavaScript execution, authentication, or user interaction to become visible. Prioritize converting the highest-value content to server-rendered or statically generated HTML.
PDF content inventory: List all PDFs linked from your website that contain strategically important content. Evaluate which should be converted to HTML pages.
Robots.txt and crawl permission review: Confirm that no crawl directives inadvertently block AI crawlers from accessing key content.
FAQ
Does good Google SEO guarantee AI readability?
No. Google has invested in JavaScript rendering infrastructure that most AI systems lack. A page that ranks well in Google may return almost no content to an AI crawler that cannot execute JavaScript.
Which website architectures have the worst AI readability?
Single-page applications built entirely in client-side React, Vue, or Angular with no server-side rendering have the worst baseline AI readability. Next.js or Nuxt.js applications using client-side rendering mode are similarly affected. Static sites and server-rendered applications have the best baseline readability.
Is structured data required for AI visibility?
Not strictly required, but highly influential. Without structured data, AI systems must infer meaning from content context and formatting — an unreliable process that produces incomplete representations. Structured data provides explicit signals that AI systems can use directly.
Can we add structured data without rebuilding our website?
In most cases, yes. Structured data can be added via Google Tag Manager, injected through CMS plugins, or added directly to page templates without significant architectural changes. It is usually one of the fastest improvements available.
How do we test whether AI systems can read our website?
Use command-line tools or online services that fetch raw HTML without JavaScript execution (like curl or tools that emulate AI crawlers). Compare the returned HTML to what a browser renders. The difference represents content invisible to most AI systems.
Should we unpublish all gated content?
No, but you should audit the trade-off. For content that primarily generates AI visibility value — thought leadership, capability explanations, research findings — consider publishing freely accessible HTML versions. For content where lead generation is the primary objective, gating may remain appropriate while accepting the AI visibility cost.
How often does AI readability need to be reviewed?
When website architecture changes, new sections are added, or the CMS is updated. Also when new AI retrieval tools become prominent — their crawling behavior may differ from previous systems, requiring reassessment.
Does page speed affect AI crawlability?
Less directly than for user experience, but crawl timeouts can cause AI systems to abandon slow-loading pages before content renders. Fast server response times reduce this risk.
References
[1] The Rise Of Ai Search And What It Means For Seo - https://www.searchenginejournal.com/the-rise-of-ai-search-and-what-it-means-for-seo/
[2] Optimizing For Ai Search Engines - https://www.semrush.com/blog/ai-search-optimization/
[3] How Ai Synthesizes Information From Multiple Sources - https://www.contentatscale.ai/blog/ai-content-synthesis/
[4] Zero Click Searches The Future Of Seo - https://moz.com/blog/zero-click-searches-future-of-seo
[5] Ai Search Analytics A Roadmap To Ai Visibility In 2026 - https://www.wpfastestcache.com/blog/ai-search-analytics-a-roadmap-to-ai-visibility-in-2026/
[6] Generative Engine Optimization Geo Strategies - https://www.siegemedia.com/strategy/generative-engine-optimization
[7] Ai Visibility Tools Comparison 2026 - https://www.searchparty.com/blog/ai-visibility-tools-comparison-2026
[8] Creating Content For Ai Visibility - https://www.hubspot.com/marketing/ai-content-optimization
[9] Measuring Success In The Age Of Ai Search - https://www.conductor.com/blog/measuring-ai-search-success/
[10] Structured Data And Ai Readability - https://schema.org/docs/gs.html
About the Author
Sergio D'Alberto is the founder of ABL (AI.BUSINESS.LIFE.), an AI strategy and adoption advisory. His work focuses on helping leadership teams navigate AI governance, visibility strategy, and responsible adoption.
Prior to founding ABL, Sergio spent 16 years at Microsoft, most recently in Azure Engineering.
Related Essays
What AI Actually Does When a Customer Asks for a Recommendation About Your Business
Most organizations have no idea what happens inside an AI system when a customer asks about them. This essay maps the mechanics of AI recommendation generation — and what organizations must do to influence the outcome.
AI Does Not Rank. It Rewrites.
Understanding the fundamental shift from ranked search results to AI-synthesized answers and what this means for organizational visibility and competitive positioning.
AI Visibility Is Not a Marketing Problem: Why It Belongs on the Leadership Agenda
AI visibility is increasingly misclassified as a marketing function. This essay explains why it is a governance and leadership issue — and what happens when organizations treat it otherwise.