Die unsichtbare Website: Warum KI-Crawler die meisten modernen Unternehmenswebsites nicht lesen können
Die meisten modernen Unternehmenswebsites sind für KI-Crawler technisch unsichtbar. Dieser Essay erklärt die strukturellen Gründe und was Organisationen tun müssen, um für die Systeme lesbar zu werden, die heute Geschäftsentscheidungen vermitteln.

Ein Unternehmen kann eine gut gestaltete Website, ein Content-Team, ein funktionierendes SEO-Programm und konstanten Traffic haben, und für die KI-Systeme, die heute Geschäftsentscheidungen vermitteln, trotzdem faktisch unsichtbar sein. Das ist kein Content-Problem. Es ist ein strukturelles, und die meisten Organisationen haben es noch nicht erkannt.
Die wichtigsten Punkte
- Moderne, JavaScript-lastige Websites sind für KI-Crawler oft unlesbar, weil diese kein clientseitiges Rendering ausführen können.
- Dynamische Inhalte, die erst nach dem Seitenaufbau laden (Menüs, Produktbeschreibungen, Preise, Leistungsdetails), werden von KI-Systemen häufig vollständig übersehen.
- Lücken bei strukturierten Daten führen dazu, dass KI-Systeme nicht zuverlässig erkennen, was eine Organisation ist, was sie tut und wen sie bedient.
- KI-Crawler und Suchmaschinen-Crawler sind nicht dasselbe. Eine Optimierung für Google garantiert keine KI-Lesbarkeit.
- Single-Page-Applications (SPAs) auf Basis von React, Vue oder Angular stellen die KI-Inhaltsextraktion vor besondere Herausforderungen.
- PDF-lastige und zugangsbeschränkte Content-Strategien verbergen organisatorisches Wissen faktisch vor KI-Systemen, die unstrukturierte Dokumente nicht authentifizieren oder zuverlässig auslesen können.
- Die technische Lücke ist behebbar, erfordert aber Infrastrukturentscheidungen, die über das Marketing hinaus in die Entwicklung reichen.
- Organisationen, die die technische KI-Lesbarkeit jetzt angehen, bauen einen kumulativen Vorteil auf, während die KI-vermittelte Entdeckung wächst.
Kurzantwort
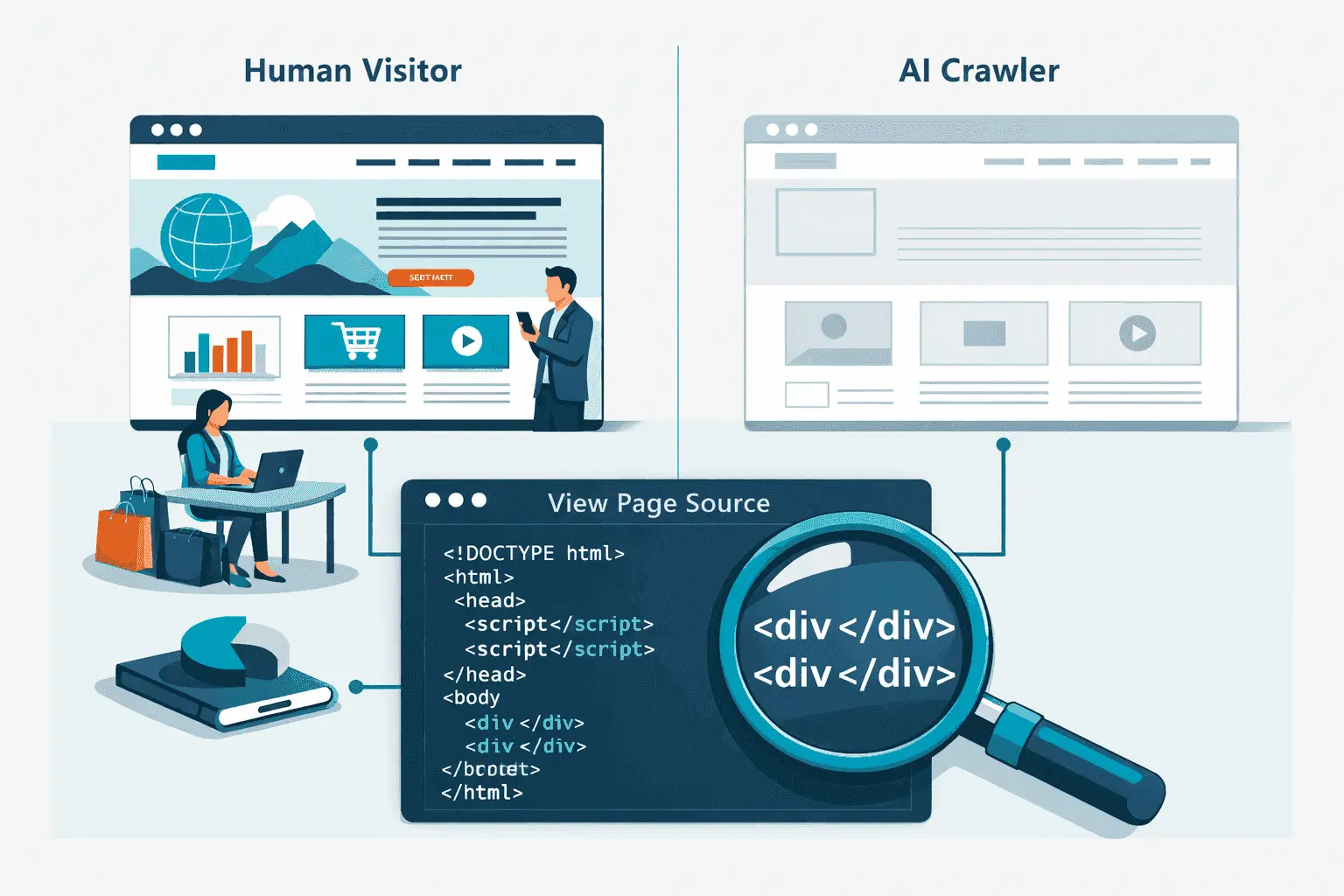
Die meisten KI-Systeme hinter Werkzeugen wie ChatGPT, Perplexity und Claude bauen ihr Wissen aus Webinhalten auf, die beim Training gesammelt oder in Echtzeit abgerufen werden. Wenn Ihre Website ihre Inhalte über JavaScript rendert, das erst im Browser ausgeführt wird, Inhalte dynamisch nach der ersten Seitenanfrage lädt oder eine Anmeldung für zentrale Informationen verlangt, treffen KI-Crawler auf eine leere oder unvollständige Seite. Der Inhalt existiert für menschliche Besucher, aber nicht für die Maschinen, die heute beeinflussen, wie Ihre Organisation gefunden, beschrieben und empfohlen wird.
Wie sich KI-Crawler von Suchmaschinen-Crawlern unterscheiden
Die Annahme, dass eine in der Google-Suche gut platzierte Website auch für KI-Systeme lesbar ist, stimmt nicht. Google hat stark in JavaScript-Rendering-Infrastruktur investiert: Der Googlebot kann JavaScript ausführen, auf das Laden dynamischer Inhalte warten und das Ergebnis indexieren. Die meisten KI-Trainings-Crawler und Abrufsysteme können das nicht.
Klassische KI-Trainings-Crawler funktionieren ähnlich wie frühe Such-Bots: Sie holen das rohe HTML einer Seite und extrahieren den Text, der in dieser ersten Antwort vorhanden ist. Wenn eine React- oder Next.js-Anwendung eine nahezu leere HTML-Hülle mit einem <div id="root"></div> zurückgibt und ihre Inhalte erst nach dem Rendern per JavaScript lädt, erhält der Crawler fast nichts.
Retrieval-augmentierte KI-Systeme, die Live-Webinhalte abrufen, stehen vor demselben Problem. Wenn Perplexity oder ein ChatGPT-Browsing-Plugin Ihre Website abruft, um die Frage einer Nutzerin zu beantworten, holt es in der Regel das HTML und analysiert es. JavaScript-Ausführung ist in den meisten Abruf-Pipelines begrenzt oder nicht vorhanden.
Die praktische Folge: Eine vollständig als Single-Page-Application gebaute Unternehmenswebsite kann im Browser hervorragend aussehen und in Google ordentlich ranken, während sie jedem KI-System, das sie zu lesen versucht, nahezu keinen nutzbaren Inhalt liefert.
Das Problem mit JavaScript-Rendering
Die Mehrheit moderner Unternehmenswebsites basiert auf JavaScript-Frameworks: React, Vue, Angular, Next.js im clientseitigen Rendering-Modus. Diese Frameworks liefern Anwendungen statt Dokumente. Der Server sendet minimales HTML und ein grosses JavaScript-Bundle. Der Browser führt das JavaScript aus, holt Daten von APIs und setzt die sichtbare Seite zusammen.
Diese Architektur erzeugt mehrere Stellen, an denen die KI-Lesbarkeit scheitert.
Hüllen-HTML ohne Inhalt: Fordert ein KI-Crawler eine Seite an, erhält er womöglich nur die Anwendungshülle, also Navigationsplatzhalter, einen leeren Hauptcontainer und Script-Tags. Keiner der eigentlichen Seiteninhalte ist in der ersten HTML-Antwort enthalten.
Clientseitiges Laden von Daten: Leistungsbeschreibungen, Team-Profile, Fallstudien, Preisinformationen und andere strategisch wichtige Inhalte werden oft erst nach dem Aufbau der Hülle von einer separaten API geladen. KI-Crawler, die kein JavaScript ausführen, lösen diese API-Aufrufe nie aus und sehen die Inhalte nie.
Lazy Loading und Scroll-Trigger: Inhalte, die beim Herunterscrollen laden, sieht ein Crawler nie, der kein Scrollverhalten simuliert. Produktkataloge, Referenz-Abschnitte und ausführliche Leistungsbeschreibungen werden häufig so umgesetzt.
Inhalte in Modals und Tabs: Informationen hinter UI-Interaktionen, etwa ein Klick auf einen Tab für Leistungsdetails oder ein Modal für eine Fallstudie, sind für Crawler, die nicht mit der Seite interagieren, strukturell unerreichbar.
Server-seitiges Rendering und statische Generierung als Lösungen
Der zuverlässigste Weg zu KI-Lesbarkeit besteht darin, dass zentrale Inhalte bereits in der ersten HTML-Antwort des Servers vorhanden sind, bevor irgendein JavaScript ausgeführt wird. Zwei Ansätze lösen das.
Server-seitiges Rendering (SSR) erzeugt das vollständige HTML jeder Seite auf dem Server für jede Anfrage und liefert jedem Client, auch KI-Crawlern, in der ersten Antwort vollständige Inhalte. Next.js, Nuxt.js und SvelteKit unterstützen SSR. Organisationen, die diese Frameworks im clientseitigen Modus nutzen, können ohne Neubau der Anwendung auf SSR umstellen.
Statische Generierung (Static Site Generation, SSG) rendert Seiten zur Build-Zeit vor und erzeugt statische HTML-Dateien, die jeder Crawler direkt lesen kann. Für Inhalte, die sich nicht bei jeder Anfrage ändern (Leistungsbeschreibungen, Team-Seiten, Fallstudien, Blogbeiträge), ist die statische Generierung der einfachste und robusteste Weg zu KI-Lesbarkeit.
Das Grundprinzip lautet: Wenn ein Inhalt wichtig genug ist, dass ihn eine potenzielle Kundin lesen soll, muss er in dem HTML stehen, das ein Server ausliefert, und nicht erst später vom Browser-JavaScript zusammengesetzt werden.
Strukturierte Daten: Die Ebene, die die meisten überspringen
Selbst Websites mit lesbarem HTML scheitern oft an der nächsten Ebene des KI-Verständnisses: an strukturierten Daten. Strukturierte Daten sind maschinenlesbare Auszeichnungen im Seiten-HTML, die KI-Systemen und Suchmaschinen mitteilen, worum es auf einer Seite geht, wer die Organisation ist und welche Informationen dargestellt werden.
Schema.org-Markup ist der zentrale Standard. Relevante Schema-Typen für die meisten Unternehmenswebsites sind unter anderem:
Organization: definiert Firmenname, Beschreibung, Gründungsdatum, Mitarbeitendenzahl, Branche, Kontaktdaten und Social-Media-ProfileService: beschreibt konkrete Leistungen, ihre Kategorien und ihre ZielgruppenPerson: schreibt Fachinhalte namentlich genannten Personen mit beruflichen Qualifikationen zuFAQPage: kennzeichnet FAQ-Inhalte in einem Format, das KI-Systeme direkt extrahieren könnenBreadcrumbList: hilft KI-Systemen, Seitenstruktur und Inhaltshierarchie zu verstehenArticleundBlogPosting: kennzeichnet redaktionelle Inhalte mit Autor, Datum und Themen-Metadaten
Ohne dieses Markup müssen KI-Systeme aus Formatierung und Kontext erschliessen, was Inhalte bedeuten, ein unzuverlässiger Vorgang, der häufig unvollständige oder ungenaue Darstellungen erzeugt. Mit dem Markup erhalten KI-Systeme explizite, strukturierte Signale dazu, was die Organisation ist und was jede Seite enthält.
Die meisten Unternehmenswebsites haben strukturierte Daten nur teilweise oder gar nicht umgesetzt. Selbst Organisationen mit aktivem SEO-Programm beschränken strukturierte Daten oft auf grundlegendes Organization-Schema und lokale Auszeichnung und verpassen die reichere Umsetzung, die eine korrekte KI-Repräsentation stützt.
Gated Content und das Problem der Wissens-Sichtbarkeit
Viele Organisationen verbergen ihre autoritativsten Inhalte hinter Anmeldeschranken: Whitepapers, Forschungsberichte, ausführliche Fallstudien und technische Dokumentation. Diese Inhalte verkörpern die tatsächliche Expertise der Organisation, also genau das Material, das, wenn KI-Systeme es lesen könnten, eine starke und korrekte KI-Repräsentation erzeugen würde.
KI-Systeme können es nicht lesen. Anmeldeschranken sind für Crawler absolute Barrieren.
Die strategische Folge: Organisationen, die ihre besten Inhalte zur Lead-Gewinnung verbergen, tauschen KI-Sichtbarkeit gegen Kontaktdaten. In Märkten, in denen die KI-vermittelte Entdeckung wächst, wird dieser Tausch zunehmend ungünstiger. Ein verborgenes Whitepaper erzeugt null KI-Sichtbarkeit. Derselbe Inhalt, frei zugänglich als Artikel veröffentlicht, trägt bei jedem Crawl zur KI-Repräsentation bei.
Das bedeutet nicht, jeglichen Gated Content abzuschaffen. Es bedeutet, bewusst zu wählen, was für die KI-Lesbarkeit öffentlich sein soll, im Bewusstsein, dass die frei zugängliche Version des organisatorischen Wissens prägt, wie KI-Systeme die Organisation gegenüber potenziellen Kundinnen, Investoren und Partnern beschreiben.
PDF-Inhalte als struktureller blinder Fleck
PDFs bringen ein verwandtes Problem mit sich. Viele Organisationen veröffentlichen wichtige Inhalte (Geschäftsberichte, Leistungspräsentationen, Produktspezifikationen, Leitfäden) als PDF-Dateien. KI-Crawler können PDF-Text manchmal lesen, aber die Zuverlässigkeit der Extraktion schwankt stark, die Formatierung stört oft den Textfluss, und PDFs bieten keine strukturierte Auszeichnung.
Noch entscheidender: PDFs werden von KI-Systemen selten so tiefgehend erfasst wie HTML-Inhalte. Eine Produktspezifikation, die in einem PDF vergraben ist, taucht in KI-erzeugten Unternehmenszusammenfassungen fast nie auf. Dieselbe Spezifikation, als HTML-Seite mit passendem Schema-Markup veröffentlicht, schon.
Die operative Folge: Jeder Inhalt, der nur als PDF existiert, sollte als halb-unsichtbar für KI-Systeme gelten. Organisationen, die auf PDF-basierte Content-Strategien setzen (verbreitet in professionellen Dienstleistungen, im Finanzwesen und in der Unternehmens-IT), haben eine erhebliche Lücke bei der KI-Lesbarkeit, die eine Umwandlung in zugängliches HTML erfordert.
Praktisches Audit: Was Sie prüfen sollten
Wer die eigene KI-Lesbarkeit einschätzen will, sollte ein fokussiertes technisches Audit über fünf Dimensionen durchführen.
JavaScript-Rendering-Test: Rufen Sie Ihre wichtigsten Seiten mit einem Werkzeug ab, das das rohe HTML ohne JavaScript-Ausführung zurückgibt. Vergleichen Sie das mit dem, was ein Browser darstellt. Die Differenz ist der Inhalt, den KI-Crawler nicht sehen können.
Validierung strukturierter Daten: Nutzen Sie den Rich-Results-Test von Google oder den Schema.org-Validator, um zu prüfen, welche strukturierten Daten auf zentralen Seiten existieren. Erkennen Sie fehlende Schema-Typen und unvollständige Umsetzungen.
Kartierung der Inhaltszugänglichkeit: Bestimmen Sie, welche Inhalte Ihrer Website JavaScript-Ausführung, Anmeldung oder Nutzerinteraktion brauchen, um sichtbar zu werden. Priorisieren Sie die Umwandlung der wertvollsten Inhalte in serverseitig gerendertes oder statisch generiertes HTML.
PDF-Inhaltsinventar: Listen Sie alle von Ihrer Website verlinkten PDFs mit strategisch wichtigem Inhalt auf. Bewerten Sie, welche in HTML-Seiten umgewandelt werden sollten.
Robots.txt- und Crawl-Berechtigungsprüfung: Stellen Sie sicher, dass keine Crawl-Direktiven KI-Crawler versehentlich vom Zugriff auf zentrale Inhalte ausschliessen.
Häufige Fragen
Garantiert gutes Google-SEO KI-Lesbarkeit?
Nein. Google hat in JavaScript-Rendering-Infrastruktur investiert, die den meisten KI-Systemen fehlt. Eine in Google gut platzierte Seite kann einem KI-Crawler, der kein JavaScript ausführt, nahezu keinen Inhalt liefern.
Welche Website-Architekturen haben die schlechteste KI-Lesbarkeit?
Single-Page-Applications, vollständig in clientseitigem React, Vue oder Angular ohne server-seitiges Rendering, haben die schlechteste Grund-Lesbarkeit. Next.js- oder Nuxt.js-Anwendungen im clientseitigen Modus sind ähnlich betroffen. Statische Seiten und server-seitig gerenderte Anwendungen haben die beste Grund-Lesbarkeit.
Sind strukturierte Daten für KI-Sichtbarkeit erforderlich?
Nicht zwingend, aber höchst einflussreich. Ohne strukturierte Daten müssen KI-Systeme die Bedeutung aus Kontext und Formatierung erschliessen, ein unzuverlässiger Vorgang mit unvollständigen Darstellungen. Strukturierte Daten liefern explizite Signale, die KI-Systeme direkt nutzen können.
Können wir strukturierte Daten ohne Neubau der Website ergänzen?
In den meisten Fällen ja. Strukturierte Daten lassen sich über den Google Tag Manager einbinden, über CMS-Plugins einfügen oder direkt in Seitenvorlagen ergänzen, ohne wesentliche architektonische Änderungen. Es ist meist eine der schnellsten verfügbaren Verbesserungen.
Wie testen wir, ob KI-Systeme unsere Website lesen können?
Nutzen Sie Kommandozeilen-Werkzeuge oder Online-Dienste, die rohes HTML ohne JavaScript-Ausführung abrufen (etwa curl oder Werkzeuge, die KI-Crawler nachbilden). Vergleichen Sie das zurückgegebene HTML mit dem, was ein Browser darstellt. Die Differenz ist der für die meisten KI-Systeme unsichtbare Inhalt.
Sollten wir sämtliche Gated-Content-Inhalte freigeben?
Nein, aber Sie sollten den Zielkonflikt prüfen. Für Inhalte, die vor allem KI-Sichtbarkeit erzeugen (Thought Leadership, Erklärungen zu Fähigkeiten, Forschungsergebnisse), sollten Sie frei zugängliche HTML-Versionen erwägen. Bei Inhalten, deren Hauptziel die Lead-Gewinnung ist, kann die Schranke angemessen bleiben, unter Inkaufnahme der Kosten bei der KI-Sichtbarkeit.
Wie oft muss die KI-Lesbarkeit überprüft werden?
Wenn sich die Website-Architektur ändert, neue Bereiche hinzukommen oder das CMS aktualisiert wird. Auch wenn neue KI-Abrufwerkzeuge an Bedeutung gewinnen, kann sich ihr Crawl-Verhalten von früheren Systemen unterscheiden und eine erneute Prüfung erfordern.
Beeinflusst die Seitengeschwindigkeit die KI-Crawlbarkeit?
Weniger direkt als die Nutzererfahrung, aber Crawl-Timeouts können dazu führen, dass KI-Systeme langsam ladende Seiten abbrechen, bevor der Inhalt erscheint. Schnelle Server-Antwortzeiten verringern dieses Risiko.
Quellen
[1] The Rise Of Ai Search And What It Means For Seo - https://www.searchenginejournal.com/the-rise-of-ai-search-and-what-it-means-for-seo/
[2] Optimizing For Ai Search Engines - https://www.semrush.com/blog/ai-search-optimization/
[3] How Ai Synthesizes Information From Multiple Sources - https://www.contentatscale.ai/blog/ai-content-synthesis/
[4] Zero Click Searches The Future Of Seo - https://moz.com/blog/zero-click-searches-future-of-seo
[5] Ai Search Analytics A Roadmap To Ai Visibility In 2026 - https://www.wpfastestcache.com/blog/ai-search-analytics-a-roadmap-to-ai-visibility-in-2026/
[6] Generative Engine Optimization Geo Strategies - https://www.siegemedia.com/strategy/generative-engine-optimization
[7] Ai Visibility Tools Comparison 2026 - https://www.searchparty.com/blog/ai-visibility-tools-comparison-2026
[8] Creating Content For Ai Visibility - https://www.hubspot.com/marketing/ai-content-optimization
[9] Measuring Success In The Age Of Ai Search - https://www.conductor.com/blog/measuring-ai-search-success/
[10] Structured Data And Ai Readability - https://schema.org/docs/gs.html
Über den Autor
Sergio D'Alberto ist der Gründer von ABL (AI.BUSINESS.LIFE.), einer Beratung für KI-Strategie und -Einführung. Seine Arbeit hilft Führungsteams, KI-Governance, Sichtbarkeitsstrategie und verantwortungsvolle Einführung zu meistern.
Vor der Gründung von ABL war Sergio 16 Jahre bei Microsoft, zuletzt im Azure Engineering.
Weiterführende Essays
KI rankt nicht. Sie schreibt um.
Der grundlegende Wandel von gerankten Suchergebnissen zu KI-synthetisierten Antworten und was er für die Sichtbarkeit und die Wettbewerbspositionierung von Organisationen bedeutet.
Was KI tatsächlich tut, wenn ein Kunde nach einer Empfehlung zu Ihrem Unternehmen fragt
Die meisten Organisationen wissen nicht, was in einem KI-System geschieht, wenn ein Kunde nach ihnen fragt. Dieser Essay zeigt die Mechanik der KI-Empfehlungserzeugung und was Organisationen tun müssen, um das Ergebnis zu beeinflussen.
Wenn KI für Ihre Kundschaft entscheidet: Der Aufstieg KI-vermittelter Entscheidungen
KI-Systeme vermitteln Geschäftsentscheidungen zunehmend, bevor Menschen überhaupt einbezogen werden. Das schafft neue Governance-Pflichten für die Sichtbarkeit und Wettbewerbspositionierung von Organisationen.